Argo Rollouts
개요

쿠버네티스의 디플로이먼트 업데이트 전략을 훨씬 확장시키는 애드온.
디플로이먼트의 업데이트 전략은 정말 구지다(고 생각한다).
실질적으로 간단하게 할 수 있는 것은 롤링 업데이트 뿐이고, 블루그린, 카나리 등의 방법을 사용하기 위해서는 직접 커스텀하는 수밖에 없는데 이걸 도와주는 것이 바로 아르고 롤아웃.
다른 아르고 친구들이랑 마찬가지로 CRD를 제공하며 컨트롤러로 이를 제어한다.
구체적으로 다음의 기능들을 가진다.
- 블루그린, 카나리 등의 다양한 배포 전략
- 위 전략들에 기반한 점진적 배포(Progressive Delivery)
- 배포를 진행하며 메트릭 기반, 혹은 명령어 설정 등을 통해 분석(Analysis) 기능 제공
- 인그레스나 서비스 메시와도 결합 가능.
- 관측 가능성 기반으로도 동작!
레플리카셋을 관리한다는 점에서는 디플로이먼트와 같기 때문에, 정말 디플의 확장처럼 생각할 만한 애드온이라고 생각한다.
점진적 배포 툴로 Flagger라는 녀석도 있는데, 플래거는 설정은 간단하지만 사용성 측면에서는 롤아웃이 압승이라 생각한다.
아키텍처
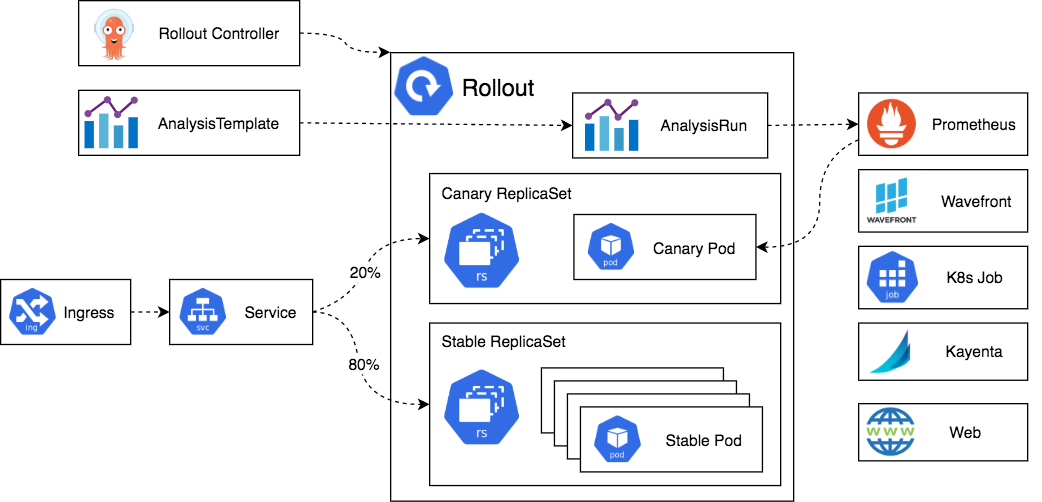
이 친구.. 너무 간단해서 전체 구조도도 딱히 없다..!
아르고 롤아웃 컨트롤러가 있고, 이 친구가 아르고 롤아웃 관련 CRD를 추적하며 레플리카셋을 건드린다.
근데 여기에 트래픽 라우팅, 메트릭 기반 점진적 배포 등 다양하게 건드릴 수 있게 해줄 뿐인 것이다.
그래서 근본 동작 방식도 디플로이먼트와 크게 다를 게 없다.
업데이트를 해야 하는 상황이 생기면 일단 새로운 레플리카셋을 만든다.
그리고 일반 디플로이먼트로는 할 수 없는, 블루그린이나 카나리를 해주는 것이다.
여기에 추가적으로 위에서 잠시 말한 Analysis를 중간에 끼어서 진행하는 것이 가능하다.
자세한 건 [[#AnalysisTemplate, ClusterAnalysisTemplate]] 참고.
동작 방식
업그레이드를 한다는 것은 결국 레플리카셋을 새로 만든다는 것과 같다.
이때 레플리카셋은 각자 고유한 pod-template-hash 값이 있는데, 기본적으로 아르고 롤아웃은 이 값을 활용한다.
구체적으로 자신의 파드로 트래픽을 보내는 서비스의 라벨 셀렉터에 해시 값을 추가시켜 명확하게 트래픽을 관리한다.
블루 그린 동작
먼저 블루와 그린 각각의 서비스를 두고, 처음에는 둘다 블루 버전을 가리키도록 세팅된다.
업데이트가 시작되어도 그린이 준비 상태가 되기 전까지 명확하게 블루로만 트래픽이 전달되도록 한다.
그린이 준비 상태가 됐을 때는 바로 서비스의 라벨에 해시 값을 딸깍 바꿔 트래픽을 바꿔준다.
이후에는 천천히 블루 워크로드를 스케일 다운하는 절차를 거친다.
이때 천천히 스케일 다운하는 이유는 서비스의 셀렉터를 바꿈으로 인해 일어나는 엔드포인트슬라이스 업데이트 속도 때문이다.
kube-proxy#프록시 모드에 나오듯 결국 서비스는 노드의 iptables로 (흔히) 관리되는데 이게 업데이트에 속도가 조금 걸릴 수 있기에 이때 발생할 에러를 방지하려는 것이다.
카나리 동작
카나리 동작도 마찬가지로 이전 버전(stable)과 새 버전(canary)을 가리키는 서비스를 각각 둔다.
그리고 배포가 진행되는 동안 여러 단계를 밟으면서 각 레플리카의 개수를 늘리거나 줄이는가 하면 아예 각 버전으로 흐르는 트래픽의 양을 조절하는 등의 작업을 한다.
카나리 역시 마찬가지로 배포가 끝나면 이전 버전을 천천히 스케일 다운한다.
사전지식으로, 배포가 이뤄지는 과정에서 이전 단계에서 다음 단계로 넘어가는 작업을 promotion이라고 부른다.
블루그린으로 치면 블루와 그린 사이에 트래픽을 전환하는 작업이 프로모션이다.
카나리에서는 각 단계가 전부 프로모션이라고 보면 된다.
이 작업은 자동으로 되게 할 수도, 사용자가 직접 지정하도록 할 수도 있다.
abort는 배포를 중간에 그만두는 행위, 즉 중단을 말한다.
배포 간 문제가 생겨서 이전 버전으로 롤백되는 행위는 전부 abort라고 보면 된다.
잠깐! 다른 아르고 시리즈와의 비교점
아르고CD, 아르고 워크플로우 등은 자신들만의 api가 따로 있고 이에 맞춰 api 서버가 따로 존재한다.
그래서 각자 인증 인가에 대한 설정이 존재하며, api를 통해 요청을 보내는 것도 가능하다.
그러나 이 녀석은 api라는 게 없다.
정말 순전히 crd를 관리하는 컨트롤러가 있는 게 끝이다!
웹 ui를 제공해주긴 하나, 인증 로직이나 그런 것이 아예 없는 이유가 그래서이다.
또한 다른 애드온들은 꾸역꾸역 절대로 kubectl 플러그인을 내주지 않는데, 이 녀석만 플러그인으로 존재하는 것도 이 이유인 게 아닐까 싶다.
아무튼 본격적으로 아르고 롤아웃 사용법을 알아보자.
Rollout
아르고 워크플로우마냥, 이 친구도 핵심 리소스는 롤아웃이다. 이름에 참 충실한 친구들
apiVersion: argoproj.io/v1alpha1
kind: Rollout
metadata:
name: rollouts-demo
spec:
replicas: 5
strategy:
canary:
steps:
- setWeight: 20
- pause: {}
- setWeight: 40
- pause: {duration: 10}
- setWeight: 60
- pause: {duration: 10}
- setWeight: 80
- pause: {duration: 10}
revisionHistoryLimit: 2
selector:
matchLabels:
app: rollouts-demo
template:
metadata:
labels:
app: rollouts-demo
spec:
containers:
- name: rollouts-demo
image: argoproj/rollouts-demo:blue
ports:
- name: http
containerPort: 8080
protocol: TCP
resources:
requests:
memory: 32Mi
cpu: 5m
생긴 게 진짜 디플로이먼트 양식과 판박인데 대신 strategy 필드로 할 수 있는 게 많아보인다!
이제부터 이 전략 필드를 어떤 식으로 작성해야 하는지 구체적으로 알아볼 것이다.
strategy
일단 이 필드는 블루그린과 카나리 크게 두 가지가 가능하다.
blueGreen
strategy:
blueGreen:
# 업데이트 간 관리 대상이 될 서비스 - 이것만 필수 옵션
activeService: rollout-bluegreen-active
# 프로모션 이전, 그린에 트래픽을 보낼 수 있도록 테스트용으로 사용할 미리보기 서비스
previewService: rollout-bluegreen-preview
# 그린 만들어지고 알아서 라우팅 전환되도록(promotion) 막고 싶다면 false
# `kubectl argo rollouts promote ROLLOUT`으로 수동 전환
autoPromotionEnabled: false
autoPromotionSeconds: *int32
antiAffinity: object
prePromotionAnalysis: object
postPromotionAnalysis: object
previewReplicaCount: *int32
scaleDownDelaySeconds: *int32 # 기본 30초
scaleDownDelayRevisionLimit: *int32
각 필드가 사용되는 방식을 업데이트 흐름 관점에서 보자.
activeService,previewService두 개의 서비스가 생긴다.- 유저가 업데이트를 하게 되면 그린 레플셋이 생기고
previewService가 그린 레플셋을 가리키게 된다. - 이때 그린 레플셋은
preivewReplicaCount이 설정됐을 시 해당 개수 만큼 레플을 늘린다. - 그린 레플셋이 전부 준비 상태가 되면
prePromotionAnalysis발동. - 분석 완료 후 원래 스펙에 명시된 레플리카 수로 그린이 맞춰진다.
- 이후
autoPromotionEnabled가 참이 아니면 라우팅 전환(promotion)이 자동으로 되지 않는다.autoPromotionSecondes설정돼있으면 해당 시간 이후 자동 전환
- 그리고
activeService가 그린 레플셋을 가리키게 된다. postPromotionAnaysis발동- 이 분석 작업까지 완료되면 비로소 배포가 stable된 것으로 간주된다.
scaleDownDelaySeconds시간 지나고 블루 레플셋 스케일 다운
블루그린은 알다시피 과정이 꽤나 단순하다.
- 그린을 띄우고, 이 놈들이 정상적으로 동작하는 것을 확인한다.
- 그게 확인되면 그린으로 트래픽을 라우팅한다.
- 블루를 죽인다!
이 과정 중간 중간 세부 설정을 넣을 수 있을 뿐인 것이다.
canary
strategy:
canary:
maxSurge: '25%' # 최대 늘어날 수 있는 개수
maxUnavailable: 0 # 최대로 줄어들 수 있는 개수
steps:
- setWeight: 10 # 새 버전을 10퍼센트로 맞춘다.
- pause:
duration: 1h # 1 hour
- setWeight: 20
- pause: {} # 이렇게 돼있으면 수동으로 풀어야한다.
기본적으로 카나리 방식에선 steps 필드에 각각 단계를 작성한다.
steps 필드를 아예 안 해도 되는데, 그러면 그냥 롤링 업데이트가 되기에 그냥 디플이랑 같은 방식으로 동작하게 된다.
setWeight와 pause 필드가 가장 기본적인 스텝 필드에 해당한다.
이때 주의할 것이 setWeight 필드인데, 실제로 해보면 이 비율에 맞춰서 카나리 버전의 레플리카가 늘어나는 것을 볼 수 있지만, 이건 엄밀하게 말해 레플리카의 가중치를 지정하는 필드가 아니다.
이 필드는 실제로 트래픽을 얼마나 보낼지를 지정하는 필드로, 아래에서 볼 트래픽 라우팅 설정과 결합하면 완전히 레플리카와 분리된 채로 트래픽 가중치를 설정하는 것이 가능하다.
strategy:
canary:
steps:
- setCanaryScale:
replicas: 3
- setCanaryScale:
weight: 25
# 기존의 setWeight에 해당하는 값으로 맞춰짐
- setCanaryScale:
matchTrafficWeight: true
이렇게 setCanaryScale이라는 필드가 있는데, 이게 진짜 레플리카의 개수를 조정하는 필드이다!
첫번째 스탭에서는 고정적으로 새로운 버전의 레플이 3개가 될 것이다.
두번째의 경우는 전체 레플의 25퍼센트만큼 새 레플이 생긴다.
그러다 마지막에서는 기본으로 setWeight에 해당하는 개수로 맞춰지는 설정이다.
spec:
replicas: 10
strategy:
canary:
steps:
- setCanaryScale:
weight: 10
- setWeight: 90
- pause: {}
예를 들어 기존 버전에 100개의 레플리카가 있는 상태에서 위처럼 설정했다고 쳐보자.
setCanaryScale 필드가 있기 전 setWeight 필드가 있었다면, 새 버전 레플리카는 90개가 생겼을 것이다.
그러나 위의 방식에서는 레플리카 설정으로 인해 새 버전은 10개만 생긴다.
그리고 setWeight 필드를 90으로 설정했으니 실제로는 10개의 레플리카에 트래픽이 90퍼로 몰리게 되는 것이다.
아르고 롤아웃은 트래픽 관리 툴과 긴밀하게 결합되어 사용되는 것이 기본이라는 것을 꼭 명심하며 사용하자!
이런 상황이 의도된 게 아니라면, setCanaryScale.matchTrafficWeight를 꼭 잘 활용해야 한다.
spec:
strategy:
canary:
dynamicStableScale: true
abortScaleDownDelaySeconds: 600
참고로 기본 카나리 방식은 업데이트 진행 중에 이전 버전을 '아예' 스케일 다운하지 않는다.
업데이트가 중단(abort)됐을 때 바로 이전 버전으로 돌아가기 위함인데, 결과적으로는 업데이트가 끝날 때쯤 거의 블루그린만큼 자원을 소모하는 결과가 나오게 된다.
만약 이전 버전을 조금씩 스케일 다운시키고 싶다면 dynamicStableScale을 참으로 설정하면 된다.
이 설정이 들어가면 중단(abort)이 났을 때도 즉각 전환되진 않고 천천히 돌아가게 된다.
재밌는 게, 중단돼서 돌아갈 때도 새 버전이 바로 스케일 다운되게 하고 싶지 않다면 abortScaleDownDelaySeconds를 설정할 수 있다.
이밖의 추가 필드는 다음과 같다.
spec:
strategy:
canary:
analysis: object # 분석 관련
antiAffinity: object # 안티어피니티 세팅 참조
canaryService: string # 업뎃 간 카나리만 접근하게 해줄 서비스
stableService: string # 업뎃 간 이전 버전만 접근하게 해줄 서비스
maxSurge: stringOrInt
maxUnavailable: stringOrInt
trafficRouting: object # 트래픽 라우팅 참조
카나리 배포에서도 새 버전만 접근 가능한 서비스, 실제 버전을 바라보는 서비스를 따로따로 설정할 수 있다.
모든 워크로드들의 pod-template-hash(=레플리카셋 이름)가 각 서비스의 셀렉터로 추가되므로, 적절하게 트래픽이 가도록 보장된다.
canary|bluegreen.antiAffinity
strategy:
bluegreen:
antiAffinity:
requiredDuringSchedulingIgnoredDuringExecution: {}
---
strategy:
canary:
antiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
weight: 1 # Between 1 - 100
위의 필드 중에 계속 안티 어피니티가 보일 것이다.
이 설정은 이전 버전과 새 버전이 같은 노드에 세팅되지 못하도록 하는 설정이다.

이 기능이 나온 것은 클러스터 오토스케일링 때문인데, 블루그린을 예시로 들어보자.
(그린이 신버전 의미하는 거 아니었나 그림이 왜 이러지..?)
기본적으로는 노드를 꽉꽉 채워가면 업데이트가 진행되고 오토스케일러는 하나의 노드만 추가를 하는 상황이다.
업데이트가 완료되면 이전 버전이 사라지면서 클러스터 자원이 남아돌게 되고, 이에 따라 오토스케일러는 빈 패킹을 위해 파드들을 집약시키는 작업을 할 수도 있다.
그 동안은 실제 서비스 능력이 떨어지는 순간이 오게 될텐데, 이게 너무 아쉽더라는 것이다.

그래서 일찌감치 이전 버전과 새 버전이 같은 노드에 배치되지 않도록 하고자 하는 게 이 세팅이다.
업데이트가 완료되면 오토스케일러가 알아서 이전 버전 노드만 지워줄테니, 현 버전이 업데이트로 인해 영향을 받는 일이 사라지게 된다.
canary|bluegreen.trafficRouting
디플로이먼트가 하는 역할은 그저 레플리카 수를 어떻게 조절하는가가 끝이다.
트래픽을 분산하는 것은 순전히 앞단의 서비스가 책임지는데, 이는 결국 몇 개의 파드가 배치됐는가로 결정된다.
하지만! 아르고 롤아웃은 실제 트래픽을 분산하는 네트워크 툴과 연동하여 트래픽의 흐름을 조절할 수 있는 기능을 지원한다.
이를 통해 진정한 점진적 배포(Progressive Delivery)를 실현할 수 있게 된다!

위의 다양한 트래픽 제공자와 결합하여 관련한 기능을 수행하도록 해준다.
크게는 3가지 작업을 할 수 있다.
- 퍼센티지에 입각한 라우팅 처리(
setWeight) - 헤더에 입각한 라우팅 처리
- 트래픽 미러링

그러나, 막상 보면 실질적으로 모든 기능을 쓸 수 있는 것은 아직까지 Istio 뿐이다.[1]
그래서 트래픽 관리를 할 수 있다 정도로는 받아들여도 이스티오를 사용하지 않는 운영 조직이라면 큰 기능을 기대하기 어렵다는 것은 도입 전에 알아둘 필요가 있다.
물론 가중치 세팅만 해도 엄청나게 유용한 기능이라 굳이 안 쓸 이유는 없다고 생각하긴 한다.
apiVersion: argoproj.io/v1alpha1
kind: Rollout
spec:
...
strategy:
canary:
canaryService: canary-service
stableService: stable-service
trafficRouting:
managedRoutes:
- name: set-header-1
- name: mirror-route
# 어떤 제공자를 쓸 지 지정
istio:
virtualService:
name: rollouts-demo-vsvc
steps:
- setWeight: 20
- setHeaderRoute:
# 위 트래픽 라우팅에서 지정한 이름
name: "set-header-1"
match:
- headerName: Custom-Header1
headerValue:
# 셋 중에 하나 사용 가능
exact: Mozilla
prefix: Mozilla
regex: Mozilla(.*)
- pause: {}
- setHeaderRoute:
name: "set-header-1" # 비활성화
- setMirrorRoute:
name: mirror-route
percentage: 35
match:
- method:
exact: GET
path:
prefix: /
- pause: {}
- setMirrorRoute:
name: "mirror-route" # 비활성화
이 예시는 미러 라우팅과 헤더 기반 라우팅의 예시를 합쳤다.
이렇게 trafficRouting 필드를 지정함으로써, 카나리 단계에 추가할 수 있는 필드가 늘어난다!
방식은 일단 trafficRouting 필드에 관련한 설정과 제공자를 명시하는 식으로 시작한다.
이후에는 steps 필드에서 해당 설정들을 이용해주면 된다.
trafficRouting:
nginx:
stableIngress: canary-ingress
참고로 nginx ingress 설정은 이런 식으로 한다.
ALB Controller도 마찬가지.
서비스 앞단에 위치할 인그레스를 넣어주면, stable과 canary 서비스 간에 트래픽을 알아서 잘 분배해준다.
apiVersion: v1
kind: ConfigMap
metadata:
name: argo-rollouts-config
data:
trafficRouterPlugins: |-
- name: "argoproj-labs/sample-nginx" # 플러그인 이름. 아래 location과 일치하게 작성해야 함
location: "https://github.com/argoproj-labs/rollouts-plugin-trafficrouter-sample-nginx/releases/download/v0.0.1/metric-plugin-linux-amd64" # file://를 이용해 로컬에서 가져오기 가능
sha256: "08f588b1c799a37bbe8d0fc74cc1b1492dd70b2c" # 무결성 체크용!
headersFrom: # http 이용 시 인증 관련 정보를 넣어야 한다면
- secretRef:
name: secret-name
---
# 위에 headersFrom 부분의 시크릿
apiVersion: v1
kind: Secret
metadata:
name: secret-name
stringData:
Authorization: Basic <Base 64 TOKEN>
My-Header: value
트래픽 라우팅 필드에서는 다양한 제공자를 연동할 수 있지만 그것만으로 부족하다면 플러그인으로서 명시하여 사용해야 한다.
최근 개발되고 있는 게이트웨이API를 사용하는 것도 가능한데, 이에 대해서 아르고 측에서 자체적으로 결합할 수 있는 플러그인을 제공하고 있다.[2]
rollbackWindow
spec:
rollbackWindow:
revisions: 3
revisionHistoryLimit: 5
사용자가 롤백 작업을 하려고 해도 기본적으로 아르고 롤아웃은 이를 새로운 버전 업데이트로 인식한다.
사실 디플도 똑같긴 한데, 이게 특히 롤아웃에서 중요한 이유는 기존에 세팅된 모든 동작들을 고대로 수행해나가기 때문이다.
10단계쯤 되는 카나리 배포 설정을 했다고 쳐보자.
근데 급하게 롤백할 일이 생기면?
이럴 때 급하게 롤백을 할 수 있도록 윈도우를 지정할 수 있는 필드가 바로 rollbackWindow이다.
위처럼 설정하면 일단 revisionHistoryLimit에 따라 5개의 레플리카셋은 클러스터에 남아있긴 할 것이고, 그 중 최근 3개에 대해서 롤백을 한다면 이 롤백은 일련의 절차 없이 즉각 진행된다.
AnalysisTemplate, ClusterAnalysisTemplate
아르고 롤아웃의 또 하나의 강력한 기능은 바로 분석이다!
네트워크 제공자의 도움을 받아 트래픽을 라우팅하는 설정 뿐만 아니라 실제로 메트릭은 어떻게 되는지, 정말 괜찮긴 한 건지 등을 단순 readinessProbe에만 의존하지 않고 세세하게 추적하는 것이 가능하다.
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: success-rate
spec:
args:
- name: service-name
metrics:
- name: success-rate
interval: 5m
# 프메 쿼리는 벡터 형태로 오기에 인덱스 0으로 접근하는 게 커먼 케이스
successCondition: result[0] >= 0.95
failureLimit: 3
provider:
prometheus:
address: http://prometheus.example.com:9090
query: |
sum(irate(
istio_requests_total{reporter="source",destination_service=~"{{args.service-name}}",response_code!~"5.*"}[5m]
)) /
sum(irate(
istio_requests_total{reporter="source",destination_service=~"{{args.service-name}}"}[5m]
))
위 예시는 프로메테우스를 활용하는 분석 템플릿이다.
업데이트가 발생할 때 이 템플릿에 따라 분석이 진행된다.
그럼 이 템플릿은 어떻게 사용하느냐?
strategy:
canary:
analysis:
templates:
- templateName: success-rate
startingStep: 2 # 2 단계부터 분석 시작해라!
args:
- name: service-name
value: guestbook-svc.default.svc.cluster.local
---
strategy:
blueGreen:
activeService: active-svc
previewService: preview-svc
prePromotionAnalysis:
templates:
- templateName: smoke-tests
args:
- name: service-name
value: preview-svc.default.svc.cluster.local
롤아웃에서는 이런 식으로 analysis 필드에 설정을 넣어주면 템플릿을 기반으로 분석을 진행된다.
블루그린의 경우는 post, pre 머시기 그거 쓰면 된다.
그럼 업데이트 진행 시 해당 템플릿에 따라 AnalysisRun이란 리소스가 잡마냥 생기고 실제 분석을 진행한다.
args라는 필드가 보이는데, 템플릿을 사용하는 롤아웃마다 인자를 전달할 수 있도록 하는 세팅이다.
이 방식은 정확하게 말하자면 백그라운드 분석이라 하여 업데이트가 진행되는 동안 계속 뒤에서 실행된다.
그러다 failLimit을 넘기면 바로 업데이트를 abort시키게 될 것이다.
strategy:
canary:
steps:
- setWeight: 20
- pause: {duration: 5m}
- analysis:
templates:
- templateName: success-rate
args:
- name: service-name
value: guestbook-svc.default.svc.cluster.local
배포 단계에서 중간에 하나의 단계로서 분석을 진행하고 싶다면 이렇게 steps에 analysis 필드를 직접 넣어주면 된다.
유의할 점은 이 경우에는 분석 템플릿에 count라는 필드를 넣어서 명확하게 해당 분석을 몇 번 수행할지를 명시해야 한다는 것.

여기에서도 어떤 제공자로부터 메트릭을 받아 분석을 진행할지 다양한 선택을 할 수 있도록 설정돼있다.
metrics:
- name: test
provider:
job:
# 잡 리소스에 추가되는 메타데이터들
metadata:
annotations:
foo: bar
labels:
foo: bar
spec:
backoffLimit: 1
template:
spec:
containers:
- name: test
image: my-image:latest
command:
[my-test-script, my-service.default.svc.cluster.local]
restartPolicy: Never
보다시피 아예 분석용으로 잡을 사용할 수도 있다.
apiVersion: argoproj.io/v1alpha1
kind: AnalysisTemplate
metadata:
name: rates
spec:
args:
- name: service-name
metrics:
- name: success-rate
...
templates:
- templateName: error-rate
clusterScope: false
참고로 아예 이렇게 템플릿이 다른 템플릿을 활용할 수도 있다.
앱오앱, 웤오웤에 이은 템오템..
measurementRetention:
- metricName: total-5xx-errors
limit: 20
metrics:
- name: total-5xx-errors
...
메트릭 값을 유지하거나 회수하는 것에 대한 제한을 거는 것이 가능하다.
같은 분석을 여러 번 진행하는 것이 무의미하다면, 이 유지 제한을 크게 두는 것도 유효하겠다.
분석을 진행하는 것도 나름의 리소스를 소모하는 행위이기에 그렇다.
apiVersion: v1
kind: ConfigMap
metadata:
name: argo-rollouts-config
data:
metricProviderPlugins: |-
- name: "argoproj-labs/sample-prometheus" # name of the plugin, it must match the name required by the plugin so it can find its configuration
location: "file://./my-custom-plugin" # supports http(s):// urls and file://
네트워크 제공자를 플러그인으로 관리할 수 있듯이, 메트릭 제공자도 플러그인 관리가 가능하다.
Experiments
분석 템플릿은 기본적으로 이를 트리거하는 롤아웃을 필요로 한다.
근데 그냥 롤아웃과 무관한 라이프사이클을 가지는 분석을 진행하고 싶다면 이 리소스를 쓰면 된다.[3]
근데 개인적으로 이걸 굳이 왜 쓰지 하는 생각이 있어서 굳이 더 정리는 안 하겠다.
문서 상에서 사용 케이스를 보자면..
- 카옌타 스타일 분석(자동화된 분석[4])
- 이전 버전, 이후 버전만이 아니라 A/B/C 분석을 하고 싶을 때!
- 새 버전이 아예 새로운 서비스 리소스를 이용해야 하는 경우..
알람 기능
배포 완료되면 완료됐어용 알람 울리면 참 좋을 것이다.
이를 위해서는 추가적인 설정들을 추가해야만 한다.[5]
(Helm으로 설치할 시 values에서 길게 볼 수 있는 설정이다..)
apiVersion: v1
kind: ConfigMap
metadata:
name: argo-rollouts-notification-configmap
data:
# 템플릿 생략
# 트리거 생략
service.slack: |
token: $slack-token
---
apiVersion: v1
kind: Secret
metadata:
name: argo-rollouts-notification-secret
stringData:
slack-token: <my-slack-token>
그리고 이렇게 ConfigMap을 세팅해주면 된다.
configmap의 이름을 통해 롤아웃이 추적하는 거니 이름 오타내지 말자!

알람 제공자도 가지각색
설치
resource "helm_release" "argo_rollouts" {
count = var.create ? 1 : 0
repository = "https://argoproj.github.io/argo-helm"
chart = "argo-rollouts"
version = "2.39.3"
name = "argo-rollouts"
namespace = "argo-rollouts"
create_namespace = true
values = [
]
}
헬름으로 쉽게 설치 가능하다(예시는 테라폼까지 활용).
curl -LO https://github.com/argoproj/argo-rollouts/releases/latest/download/kubectl-argo-rollouts-linux-amd64
chmod +x ./kubectl-argo-rollouts-linux-amd64
sudo mv ./kubectl-argo-rollouts-linux-amd64 /usr/local/bin/kubectl-argo-rollouts
다른 아르고 시리즈와 마찬가지로 롤아웃도 조금 더 쉽게 관리할 수 있도록 커맨드를 제공하는데, 이 녀석은 처음부터 kubectl의 플러그인을 염두하고 제작됐다.[6]
그래서 kubectl로서 사용이 가능하다.
cat <<EOF >kubectl_complete-argo-rollouts
#!/usr/bin/env sh
# Call the __complete command passing it all arguments
kubectl argo rollouts __complete "\$@"
EOF
chmod +x kubectl_complete-argo-rollouts
sudo mv ./kubectl_complete-argo-rollouts /usr/local/bin/
자동완성을 하기 위해서, 추가적인 세팅이 필요했다.
근데 자동완성 관련 스크립트는 나는 아직 어떻게 동작하는지 봐도 봐도 잘 모르겠다.
관련 문서
| 이름 | noteType | created |
|---|---|---|
| Argo CD | knowledge | 2025-03-24 |
| Argo Workflows | knowledge | 2025-03-24 |
| 아르고 롤아웃과 이스티오 연계 | knowledge | 2025-04-22 |
| 8W - 아르고 워크플로우 | published | 2025-03-30 |
| 8W - 아르고 CD | published | 2025-03-30 |
| 8W - CICD | published | 2025-03-30 |
| 10W - Vault를 활용한 CICD 보안 | published | 2025-04-16 |
| 3W - 트래픽 가중치 - flagger와 argo rollout을 이용한 점진적 배포 | published | 2025-04-22 |
| E-buildKit을 활용한 멀티 플랫폼, 캐싱 빌드 실습 | topic/explain | 2025-03-30 |
참고
https://github.com/argoproj/argo-rollouts?tab=readme-ov-file#supported-traffic-shaping-integrations ↩︎
https://github.com/argoproj-labs/rollouts-plugin-trafficrouter-gatewayapi/ ↩︎
https://argoproj.github.io/argo-rollouts/features/experiment/ ↩︎
https://cloud.google.com/blog/products/gcp/introducing-kayenta-an-open-automated-canary-analysis-tool-from-google-and-netflix?hl=en ↩︎
https://github.com/argoproj/argo-rollouts/blob/master/manifests/notifications-install.yaml ↩︎
https://argo-rollouts.readthedocs.io/en/stable/installation/#kubectl-plugin-installation ↩︎